While general design principles and requirements for Intelligent Environments have been frequently discussed, we focus here on the problem of acquiring visual input for such systems. A successful system for this type of application must be visually aware of an area as large as possible in order to detect possible events, and in the same time must be able to concentrate on a certain region, where some activity of interest is in progress (for example, a person walking in a room). Within the region of interest, the system should acquire a level of detail (resolution) fine enough to allow for further processing. It is also important to have the ability of rapidly switching from a region of interest to another. Moreover, in order to track a moving object, the region of interest must be moved along fast enough to avoid losing the target. Finally, an obvious criterion is the cost of the camera systems and the supporting hardware.
Motivated by these requirements, we developed GlobeAll, a modular prototype for a vision-based Intelligent Room, which uses an electronic pan-tilt-zoom camera array. Compared to other types of camera systems, mainly mobile pan-tilt-zoom platforms, wide-angle lenses and mirror-based systems, our approach offers the best trade-off solution, in terms of cost, field of view, resolution, and response time.
1) Electronic pan-tilt-zoom camera system
We use an array of five fixed CMOS cameras, mounted on a spherical setup and oriented radially, so that they acquire a large field of view (approximately 130° both vertically and horizontally), while also maintaining some overlapping required for calibration - see Fig. 1.
 |
During an off-line calibration process, the images from each camera are registered by computing a full perspective transformation that aligns them to a common reference frame. Lens distortion parameters are also computed off-line, so that at run time the input images are continuously captured, corrected for distortion, and warped onto a two dimensional environment map (planar mosaic). Since the relative positions and orientations of the cameras in the array are fixed, all these operations are performed efficiently, by using the parameters computed during the calibration process.
In order to compensate for differences in exposure between cameras, we developed an intensity blending algorithm, based on the weighted average of pixel values over the transition regions between images. While warping images onto the mosaic, the intensity of the resulting pixel in the overlapping region is defined as a weighted sum of the intensities of corresponding pixels in the frames that overlap.
In order for our system to perform all the functions of a standard pan-tilt-zoom camera, we synthesize novel views for any given intermediate pan-tilt angles or zoom factor. The result is a virtual camera, which is functionally equivalent to a regular pan-tilt-zoom platform, but performs these operations electronically rather than mechanically. For this purpose, the appropriate portion of the planar mosaic is determined according to the desired pan-tilt angles and zoom factor, and then warped back to the novel view in the virtual camera. Two input images and a synthesized view together with the planar mosaic are shown in Fig. 2.

 (a) Two input images  (b) Virtual camera synthesized view |
 (c) Planar mosaic |
2) Background learning / foreground extraction
The second component in our system is responsible for maintaining an adaptive background model for the entire field of view, and for segmenting the foreground objects. Our approach involves learning a statistical color model of the background, which is used for detecting changes produced by occluding elements. Each background pixel value is modeled as a multi-dimensional Gaussian distribution in RGB space.The pixels detected as foreground are then grouped in connected components, so that each foreground object is represented as a planar layer (silhouette and texture). After the foreground has been detected, pixel distribution values are updated in order to account for the case of a slowly changing background. The background model is kept in mosaic space, allowing the system to detect new objects appearing anywhere in the scene, even if it happens outside the region of interest (the view of the virtual camera).
3) Tracking
The tracking component has two roles: to select the target from the objects detected in the previous step, and to follow the target motion, keeping it permanently within the region of interest. The selection process is a choice based on the size, height or color of the detected objects.As a target is selected, a pan/tilt command is issued for the virtual camera, so that it redirects the region of interest. The visual effect on screen is similar to that of a mobile camera tracking the moving object, although no mechanical movement is involved. By recording previous target positions, we adjust the speed of virtual camera according to the target speed, to ensure smooth camera movement.
4) Interpretation
From previous modules we obtain a description of the scene in terms of planar layers. These models are then augmented with semantic information by the interpretation module. Currently, this component is able to determine the 3-D trajectories of the selected target in the room and to detect simple events such as a person standing up or sitting down on a chair.The position of the person in the room is computed as follows: by knowing the floor position and detecting the person's head we determine the person's height and thus the head position in 3-D. The trajectory is then built by tracking the head, assuming that it will never be occluded. As we retrieve the position in the room based on the person's height, a simple event such as sitting on a chair is recognized by a sudden change in location. The results are shown in Fig. 3.
  (a) Input images |
  (b) Detected object |
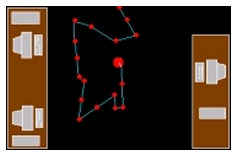 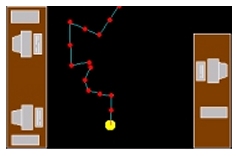 (c) Trajectory and attitude |
- Mircea Nicolescu, Gerard Medioni,
"GlobeAll: Panoramic Video for an Intelligent Room",
Proceedings of the International Conference on Pattern Recognition,
vol. I, pages 823-826, Barcelona, Spain, September 2000.
- Mircea Nicolescu, Gerard Medioni,
"Electronic Pan-Tilt-Zoom: A Solution for Intelligent Room Systems",
Proceedings of the International Conference on Multimedia and Expo,
pages 1581-1584, New York, NY, July 2000.
- Mircea Nicolescu, Gerard Medioni, Mi-Suen Lee,
"Segmentation, Tracking and Interpretation Using Panoramic Video",
Proceedings of the IEEE Workshop on Omnidirectional Vision,
pages 169-174, Hilton Head Island, SC, June 2000.