Genetic algorithms provide an efficient tool for searching large, poorly understood spaces often encountered in function optimization and machine learning [Holland, 1975,Goldberg, 1989]. The probabilistic population based nature of GA search allows GAs to be successfully applied to a variety of NP-hard problems [Goldberg, 1989,Powell et al., 1989,Caldwell and Johnston, 1991,Lin et al., 1995]. Genetic algorithms, like other search algorithms, dynamically balance exploration of the search space versus exploitation of particular areas of the space through the recombination (crossover and mutation) and selection operators respectively. When we seed a genetic algorithm's initial population with cases we alter this balance and affect performance.
A genetic algorithm explores a subset of the search space during a problem solving attempt and its population serves as an implicit memory guiding the search. Every individual generated during a search defines a point in the search space and the individual's evaluation provides a fitness. This information when stored, organized, and analyzed can be used to explain the solution, that is, tell which parts of the genotype are important, and allow a sensitivity analysis [Louis et al., 1993]. However, this information is usually discarded at the end of a GA's run and the resources spent in gaining this information are wasted. If we store this information in an explicit memory and use it in a subsequent problem solving attempt on a related problem we can tune the GA to a particular space and thus increase performance in this space assuming that problem similarity implies solution similarity. In case this assumption is false or we are unable to find solutions to similar problems the system need not fail - we are simply back to randomly initializing the population.
One early attempt at reuse can be found in Ackley's work with SIGH [Ackley, 1987]. Ackley periodically restarts a search in an attempt to avoid local optima and increase the quality of solutions. Eshelman's CHC algorithm, a genetic algorithm with elitist selection and cataclysmic mutation, also restarts search when the population diversity drops below a threshold [Eshelman, 1991]. Other related work includes Koza's automatically defined functions [Koza, 1993] and Schoenauer's constraint satisfaction method [Schoenauer and Xanthakis, 1993]. These approaches only attack a single problem not a related class of problems. More recently, Ramsey and Grefenstette come closest to our approach and use previously stored solutions to initialize a genetic algorithm's initial population and thus increase a genetic algorithm's performance in an anytime learning environment that changes with time [Ramsey and Grefensttete, 1993]. Automatic injection of the best solutions to previously encountered problems biases the search toward relevant areas of the search space and results in the reported consistent performance improvements. To our knowledge, the earliest work in combining genetic algorithms and case-based reasoning was done by Louis, McGraw, and Wyckoff who used case-based reasoning principles to explain solutions found by genetic algorithm search [Louis et al., 1993]. This paper tackles sets of similar problems and addresses the issues of which and how many cases to inject into the population. The work reported in this paper shows that injecting the best solutions to previously solved problems does not always lead to better performance and provides a possible explanation of this result.
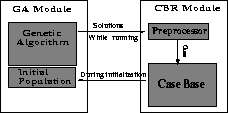
Figure 1 shows a conceptual view of a simple version of
our system. When confronted with a problem, the
CBR module looks in its case base for similar problems and their
associated solutions. If any similar problems are found a small number
of their solutions are injected into the initial population of the
genetic algorithm. The rest of the population is initialized randomly
to maintain diversity, and the GA searches from this combined
population.
The case-base does what it is best at -- memory organization; the genetic
algorithm handles what it is best at -- adaptation. The genetic algorithm also
provides a ready-made case generating mechanism as the individuals generated
during a GA search can be thought of as cases or as parts of cases. Even a
population size of 100 run for 100 generations on one problem can
generate up to
![]() cases. CBR systems usually have
difficult in finding enough cases; our problem is the opposite. We need to sift
through a large number of cases to find potential seeds for the initial
population.
cases. CBR systems usually have
difficult in finding enough cases; our problem is the opposite. We need to sift
through a large number of cases to find potential seeds for the initial
population.
There are at least three points of view when combining genetic algorithms with a case-based memory. From the case-based reasoning point of view, genetic algorithms provide a robust mechanism for adapting cases in poorly understood domains conducive to a case-based representation of domain knowledge. In addition, the individuals produced by the GA furnish a basis for generating new cases to be stored in the case-base.
From the point of view of genetic algorithms, case-based reasoning provides a long term memory store in its case-base. A combined GA-CBR system does not require a case-base to start with and can bootstrap itself by learning new cases from the genetic algorithm's attempts at solving a problem. This paper stresses the genetic algorithm point of view and addresses two questions that deal with the balance between exploration and exploitation in a search space.
What cases are relevant, or, which previously found solutions do we use to seed a genetic algorithm's population? If the ``right'' cases are injected, a GA does not have to waste time exploring unpromising subspaces because these cases provide partial, near-optimal, and/or optimal solutions. In other words, they provide good building blocks for solutions to the current problem. This is crucial if the size of a search space is extremely large since injecting appropriate cases will provide the genetic algorithm with better starting points and thus speed up search and improve performance. The population size affects the outcome when injecting ``wrong'' cases. Small population sizes may constrain the GA to a local optimum, while larger population sizes may provide enough diversity and robustness to quickly cull these cases from the population and thus only increase the time taken to reach a solution. We find therefore that in GA applications that allow only small population sizes, the cases that we inject can significantly affect solution quality.
How many cases should we inject into the initial population? This issue once again strikes at the balance between exploitation and exploration. A randomly initialized population has maximum diversity and thus maximum capacity for exploration [Louis and Rawlins, 1993]. We expect injected individuals (cases) to have a higher fitness than randomly generated individuals. Since a GA focuses search in the areas defined by high fitness individuals, we expect large numbers of high fitness individuals in an initial population to increase exploitation. This increased concentration or exploitation of a particular area can cause the GA to get stuck on a local optimum. Balancing exploitation with exploration now means balancing the number of randomly generated individuals with the number of injected individuals in the initial population.
From the machine learning point of view, using cases instead of rules to store information provides another approach to genetic based machine learning. Holland classifier systems [Holland, 1975,Goldberg, 1989] use simple string rules for long term storage and genetic algorithms as their learning or adaptive mechanism. In our system, the case-base of problems and their solutions supplies the genetic problem solver with a long term memory and leads to improvement over time.