Our system is made up of a GA module which runs in tandem with a CBR analysis module [see figure 2].
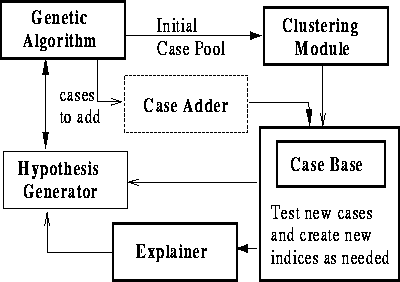
Figure: Schematic diagram of our system. The Case
Adder is still under construction.
The GA module records data for each individual in the population as it is created and evaluated. This data includes a fitness measure, the genotype, generation data, as well as some information on the individual's parents. We call this collection of data the initial case data. Though normally discarded by the time an individual is replaced, all of the case data we collect is usually contained in any GA at some point and is easy to extract.
We generally employed very basic operators and standard parameter settings in our GA experiments. However, we do use uniform crossover (Syswerda 1989) in lieu of one-point crossover. Unlike the latter, this common variant is insensitive to the defining length of a schema. The order of the schema remains important.
After creating a sufficient number of individuals over a number of generations, the initial case data are sent on to a clustering program. We use a standard hierarchical clustering program which clusters the individuals based on both the fitness and the alleles of the genotype. This clustering constructs a binary tree in which each leaf includes the data of a specific individual. The binary tree structure provides an index for the initial case-base. Figure 3 shows a small part of one such tree. The numbers at the leaves of the tree correspond to the case number (an identification number) of an individual created by the GA. Internal nodes are denoted with a ``*''. An abstract case is computed for each internal node based on the information contained in the leaves and nodes beneath it. The final case-base includes: 1) cases corresponding directly to GA individuals (at the leaves) and 2) more abstract cases made up of information generalized from the leaves.
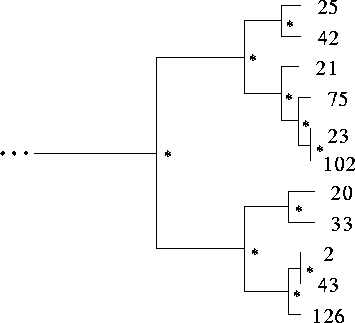
Figure: A small subsection of a typical binary tree
created by the clustering algorithm. Individuals are represented by
the numbers at the leaves. Internal nodes where abstract cases go are
denoted with a ``*''. The binary tree provides an index for the case-base.
After investigating a number of clustering techniques and clustering sets (e.g., fitness and genotype data versus fitness alone) we found that standard hierarchical clustering on fitness and genotype data produces a coherent initial index for the case-base. The fact that fitness and genotype matter the most is predicted by the BBH and is borne out by our experiments. After creating an index, several easy computations are recursively performed to flesh out the abstract cases (these computations are explained in §3).
The current version of the hypothesis generator is still fairly preliminary, and many of the initial tests of the system reported in this article were run without it. The hypothesis generator runs in tandem with the GA. Using information from the the case-base, it engineers individuals for injection into the population. In a later version, information about the measured performance of such individuals, relative to the remainder of the population, will be fed back into the hypothesis module for analysis. The success or failure of generated hypotheses can be used in decisions regarding the validity of the current case-base.
In order to support incremental updating of the case-base, we plan to install a case-adder module. The case-adder will become active only after the initial case-base is indexed. As the GA runs and new initial cases are created, an attempt will be made to fit these initial cases into the existing case-base by finding a place for them in the index tree. Periodically it may be necessary to reorganize at least parts of the case-base, but at all times it would be suitable for use by the hypothesis generator. This is discussed further in §7.3.
At the end of a run, a well-developed case-base can be used to explain how the GA came up with its answer, and why that answer is strong. Also available is knowledge about the problem space. The system can explain something about where the winning answer came from, which of its building blocks are the strongest, and which the weakest. This sort of data allows any future search of the space to be fine-tuned. It also allows for a sophisticated post facto analysis. Much of the knowledge that is usually discarded by a GA is made available in processed form for future manipulation.