|









| |
  
|
A. Space Requirements |
|
Generally speaking, the recognition performance depends
on the number of sampled views represented in the k-d tree. Increasing this
number would improve performance. However, it would also increase space
requirements as well as recognition time. To address the space requirement,
we created 3 test sets with artificial data. Each set consists of 28 groups
for all the models in the database by applying different orthographic
projections on the 3D models. 8 pixel random noise has been added to the
test views. Three k-d trees have been generated with different number of
sampled views. Table 1 shows the query accuracy for the test sets. The first
10 nearest neighbors were considered. It can be seen that we can save 97% of
space by just sacrificing 4 percent of accuracy. |
|
Table 1 Accuracy of k-d tree query for different no. of
sparse views (k=10) |
|
Query Set |
2242(2.76%) |
22582(28.13%) |
81236(100%) |
|
Set 1 |
100% |
100% |
100% |
|
Set 2 |
86% |
96% |
96% |
|
Set 3 |
96% |
93% |
100% |
|
Average |
94% |
96% |
98.7% |
|
|
|
|
B. K-d tree vs. Hashing |
|
In our previous work, we stored the space of 2D views of
the model objects in a hash table and used hashing to retrieve the
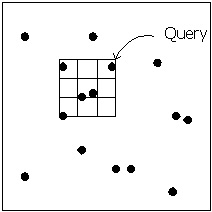
hypotheses between the models and the scene. As we know, hashing performs a
range search instead of a nearest neighbor search, recovering all points
within a given distance from the query point, as shown in Fig.1. While it is
true that most of the neighbors recovered in a range search are possible
matches, the vast majority will have a very small probability of being
valid. In general, the hypotheses with highest probability can be discovered
by observing just a few of the closest neighbors. |
|

|
|
|
(a) |
(b) |
|
Figure 1 nearest neighbor search (a) vs. range search (b) |
| |
|
|
|
Back to Top |
|