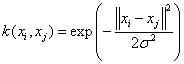|
|
|
|
Support vector regression is to construct a function that has small deviation
from actually obtained targets for all the training data, meanwhile, specify
an upper bound on the fraction of training points allowed to lie outside
of a distance from the regression estimation, called as Supposed there are training inputs
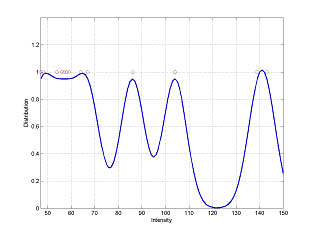
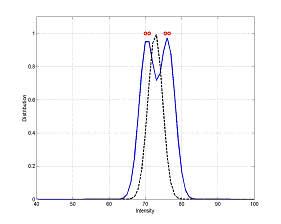
Figure 1 shows different representations for modeling background based on small training data at a fixed spatial position, such as support vector regression, supervised mixture of Gaussian distribution with 2 and 4 clusters, single Gaussian distribution. In Figure 1, training inputs and the estimated intensity distribution were described as red cycles and blue curve, respectively. In Figure 1 (d), a comparison between SVR and single Gaussian distribution labeled as blue curve and dash curve, respectively, has been shown. From Figure 1, it can be seen that support vector regression provide more accurate estimation function to fit the training data than mixture of Gaussian distribution and single Gaussian distribution.
[1] Marti Hearst, "Trends and controversies - support vector machines".
IEEE Intelligent Systems, 13(4): 18-28,1998 [2] Alex J. Smola and Bernhard Scholkopf, "A tutorial on support
vector regression", [3] J. Ma and J. Theiler, "Accurate on-line support vector regression",
Neural Computation, 15,2683-2703,2003. [4] J. W. Davis and V. Sharma, "Robust background-subtraction for
person detection in thermal imagery", IEEE,CVPR,2004 [5] J. W. Davis and M. A. Keck, "A two-stage template approach to person detection in thermal imagery", IEEE,CVPR,2005 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|