Solving combinational circuit design problems provides two valuable insights [Liu, 1996]:
A genetic algorithm can be used to design combinational circuits as
described in [Louis and Rawlins, 1991]. Consider a four-bit parity checker. It is
one of ![]() different four-input one-output
boolean functions. If we are trying to solve this class of problems, one way of
indexing (defining similarity of problems) can be as follows:
Concatenate the output bit for all possible 4-bit input combinations
counting from 0 through 15 in binary. This results in a binary string
of output bits,
different four-input one-output
boolean functions. If we are trying to solve this class of problems, one way of
indexing (defining similarity of problems) can be as follows:
Concatenate the output bit for all possible 4-bit input combinations
counting from 0 through 15 in binary. This results in a binary string
of output bits, ![]() , of length 16. Strings that are one bit
different from
, of length 16. Strings that are one bit
different from ![]() define a set of boolean functions, as do strings
that are two bits different and so on. This way of naming boolean
functions provides a simple distance metric and indexing mechanism for
the combinational circuit design problems that we consider in this
paper. Using the 4-bit parity problem as a base we define 4-1 problems
to be one bit away from
define a set of boolean functions, as do strings
that are two bits different and so on. This way of naming boolean
functions provides a simple distance metric and indexing mechanism for
the combinational circuit design problems that we consider in this
paper. Using the 4-bit parity problem as a base we define 4-1 problems
to be one bit away from ![]() , while 6-4 problems are 4 bits away from a
6-bit parity checker. Problems are constructed from
the parity problem by randomly choosing the output bits to be
changed. The fitness of a candidate circuit is the number of correct output
bits. Thus 5-bit problems would have a maximum fitness of
, while 6-4 problems are 4 bits away from a
6-bit parity checker. Problems are constructed from
the parity problem by randomly choosing the output bits to be
changed. The fitness of a candidate circuit is the number of correct output
bits. Thus 5-bit problems would have a maximum fitness of ![]() .
.
Figure 2 compares the average fitness over time of a Randomly
Initialized Genetic Algorithm (RIGA) with a Case
Initialized Genetic AlgoRithm (CIGAR). In this figure,
![]() is the 5-bit parity checker and
is the 5-bit parity checker and ![]() is a 5-8 problem. Ten
percent (
is a 5-8 problem. Ten
percent ( ![]() ) of the initial population of the GA solving
) of the initial population of the GA solving ![]() is
injected with solutions to
is
injected with solutions to ![]() . In this experiment, we chose two kinds of
. In this experiment, we chose two kinds of
![]() 's individuals for injections:
's individuals for injections:
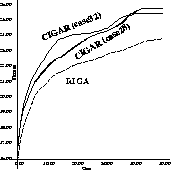
Figure: Comparing average fitness of a RIGA versus CIGAR on the 5-8
problem when injecting case28 and case32.
Focusing on maximum fitness, the tendency for lower fitness cases to produce more improvement with increasing problem distance is emphasized on larger problems. This behavior can be seen in Figure 3 which plots maximum fitness over time on the 6-8 problem. The case64 (solution to the 6-bit parity problem) injected CIGAR does not improve at all, while the case52 CIGAR shows fairly consistent improvement in maximum fitness.
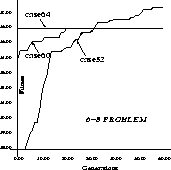
Figure: Comparing maximum performance of a RIGA with a CIGAR for
different fitness cases on the 6-8 problem.
We explored a large number of 4, 5, and 6 bit problems and the results are reported in detail in [Liu, 1996], indicating the following general trends:
Our previous results [Liu, 1996] indicate that finding the right number of cases to inject depends on a number of factors including the problem size and structure of the encoded search space. The major issue is the maintenance of diversity in the population. For our problems, when the number of injected cases passes a threshold (that depends on problem size), performance usually deteriorates over time. Since more injected cases cause the CIGAR to focus more on the sub space defined by these individuals, we would recommend going with a lower injection percentage if we are interested in long term solution quality, and with a larger percentage if we are interested in speed. A lower percentage of injected individuals allows greater population diversity leading to a more balanced exploration of the search space and thus reducing the probability of getting stuck on a local optimum. In practice, between 5 to 15 percent works well on our problems although larger percentages may also do well.