We used open shop scheduling (OSSP) and re-scheduling problems as a test problem for our system and developed a methodology to deal with problems for which indexing is not easy, that is, problems that do not lend themselves to an easy measure of similarity. The details of our encoding, operators, and genetic parameters are given in [Xu and Louis, 1996].
Instead of storing and injecting individuals with a particular fitness
depending on problem similarity, we cover our bases and save and inject a set
of individuals with different fitnesses saved at different generations of
the genetic algorithm's run on ![]() . Thus if the solutions to the problems
are ``further'' apart, the individuals from earlier generations
. Thus if the solutions to the problems
are ``further'' apart, the individuals from earlier generations![]() will probably help more than
the others. While if the solutions to the problems are ``closer,'' individuals
from later generations will help more. The genetic algorithm takes care of
culling those individuals that do not contribute to the solution of the problem
being solved. If none of the injected individuals are useful, selection quickly
removes them from the population and the (relatively large) randomly
initialized component is used as the starting point for the search and the
system just takes a little longer to find a possible solution.
will probably help more than
the others. While if the solutions to the problems are ``closer,'' individuals
from later generations will help more. The genetic algorithm takes care of
culling those individuals that do not contribute to the solution of the problem
being solved. If none of the injected individuals are useful, selection quickly
removes them from the population and the (relatively large) randomly
initialized component is used as the starting point for the search and the
system just takes a little longer to find a possible solution.
Using this methodology leads to increased performance, especially early on, and perhaps more importantly, to slow but consistent fitness increase. Solution quality is also usually better than with random initialization.
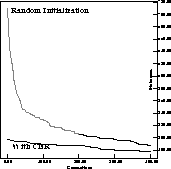
Figure: Comparing performance of a RIGA with a CIGAR for a 7x7 OSSP problem
Figure 4 compares the average performance of a CIGAR against a
randomly initialized GA on a ![]() OSSP problem. We can see that the
CIGAR starts with a much lower (better) initial makespan and that even after
300 generations CIGAR solutions are better than solutions from a randomly
initialized GA. In our experiments we note that the CIGAR always does
comparatively well in early generations and provides good schedules more
quickly than the randomly initialized GA. Out of the set of eight
OSSP problem. We can see that the
CIGAR starts with a much lower (better) initial makespan and that even after
300 generations CIGAR solutions are better than solutions from a randomly
initialized GA. In our experiments we note that the CIGAR always does
comparatively well in early generations and provides good schedules more
quickly than the randomly initialized GA. Out of the set of eight ![]() benchmark problems and five
benchmark problems and five ![]() benchmark problems, the CIGAR usually
produces schedules that are better.
benchmark problems, the CIGAR usually
produces schedules that are better.
We used the same methodology developed above to attack a set of traveling salesperson problems and study the effect of changing problem size. The encoding, crossover operator, and other parameters can be found in [Louis and Li, 1997a].
Once again, we find that injecting individuals from ![]() always leads to
better results than when running GAs with random initialization on our
problems. The experimental results imply that although problem size makes a
difference in similarity, problems can be similar enough to be useful even if
they are of different size. In fact, we sometimes got closer to the optimal
solution when using problems of different sizes than when injecting solutions
to a modified TSP of the same size where one city's location was changed.
In other words, a different sized problem with information from all cities and
all edges can help the CIGAR get better performance than a same sized problem
with missing or differing information.
always leads to
better results than when running GAs with random initialization on our
problems. The experimental results imply that although problem size makes a
difference in similarity, problems can be similar enough to be useful even if
they are of different size. In fact, we sometimes got closer to the optimal
solution when using problems of different sizes than when injecting solutions
to a modified TSP of the same size where one city's location was changed.
In other words, a different sized problem with information from all cities and
all edges can help the CIGAR get better performance than a same sized problem
with missing or differing information.
Sometimes combining solutions to dissimilar sub-problems can lead to the solution of a larger more complex problem. Consider the problem of designing control strategies for a simulated robot in a complex environment. We can break this task down into the simpler sub-tasks (learned simple behaviors) of food approach, wall following, and obstacle avoidance. Control strategies for navigating in a complex environment can then be designed by ``combining'' solutions to these simple basic behaviors.
In this situation we have to add one important step to our methodology. Control strategies for navigating in a complex environment can be designed by selecting solutions from the stored strategies evolved for basic behaviors, ranking them according to their performance in the new complex target environment and introducing them into a genetic algorithm's initial population. The genetic algorithm quickly combines these target ranked basic behaviors and finds control strategies for performing well in the more complex environment [Louis and Li, 1997b]. Injecting the best individuals found in the simple environments (Source Ranked GA (SRGA)) leads to inferior performance. In fact, the randomly initialized GA does better than the SRGA, while the target ranked GA does best. In addition, we need to make sure that the injected individuals contain at least one representative of each basic behavior. Otherwise, the missing basic behavior may have to be evolved from scratch - from the randomly initialized component of the population. Once we have individuals representing each of the basic behaviors, the rest of the candidates for injection compete for the remaining slots on the basis of their performance in the target environment. This ensures that the population is initialized with the needed variety of high performance building blocks. Figure 5 shows
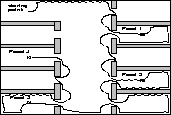
Figure: Simulated robot's path in an office environment for a circuit designed by the
TR-GA
the path of a simulated robot in the complex environment. It manages to use a strategy tailored to the environment entering all rooms with food (squares) and avoiding rooms without food.
We have provided an overview of the evidence pointing to the feasibility of
combining genetic algorithms with a case-based memory. However, we did not
test a complete system and only solved pairs of similar problems using a two
step process of solving ![]() and saving individuals, then solving
and saving individuals, then solving
![]() using individuals from
using individuals from ![]() . In the next section we
define a class of similar problems and let the combined system solve about 50
randomly generated problems from this class.
. In the next section we
define a class of similar problems and let the combined system solve about 50
randomly generated problems from this class.