The problem set is based on the number of one's in a bit string, a variation of
the one-max problem [Ackley, 1987]. We considered problems where a string of
ones was followed by a string of zeros. Consider a string of length
10. Choose a position M in this string. Let ![]() be the number of ones to
the left of M and
be the number of ones to
the left of M and ![]() the number of zeros to the right of M.
The fitness of this string is
the number of zeros to the right of M.
The fitness of this string is
![]()
We let M be the index of a problem in this class. The maximum fitness of any of the problems in this class is l, the length of the string. For example, for l = 6, there are 7 problems in this class. This set of problems was chosen for two reasons.
Initially, the system has an empty case-base and the GA starts with a randomly
initialized population. As problems are solved the case-base is built up and
used. We used a chromosome length of 100 and ran the GA with a population
size of 200 for 100 generations, storing the best individual from every
![]() generation of the GA into the case-base. We did not solve all the
101 problems in the class but restricted the problem set to
generation of the GA into the case-base. We did not solve all the
101 problems in the class but restricted the problem set to ![]() for a total of 51 possible problems. We ran the system ten times with
different random seeds and the results reported are averaged over these ten
runs.
for a total of 51 possible problems. We ran the system ten times with
different random seeds and the results reported are averaged over these ten
runs.
When confronted with a randomly generated problem ![]() from within the class
of about 50 problems the system ranks the problems in the case-base according
to distance from
from within the class
of about 50 problems the system ranks the problems in the case-base according
to distance from ![]() . We use distance proportional selection for
injection where the probability of a problem's solutions being selected for
injection is inversely proportional to distance. In fact, we simply use the
roulette wheel procedure given in Goldberg's book [Goldberg, 1989] and the
probability
. We use distance proportional selection for
injection where the probability of a problem's solutions being selected for
injection is inversely proportional to distance. In fact, we simply use the
roulette wheel procedure given in Goldberg's book [Goldberg, 1989] and the
probability
![]() of a problem
of a problem ![]() 's solutions being selected for
injection is
's solutions being selected for
injection is
![]()
where CB denotes the case-base.
When a problem is selected by this procedure we inject one of the stored
solutions to this problem into the initial population of the GA solving
![]() . The solution to be injected is again chosen depending on problem
distance. Recall that we stored the best individual from every
. The solution to be injected is again chosen depending on problem
distance. Recall that we stored the best individual from every ![]() generation. The probability of choosing a solution from a particular generation
is inversely proportional to problem distance.
generation. The probability of choosing a solution from a particular generation
is inversely proportional to problem distance.
We used linear scaling with a scaling factor of 1.2 and an elitist selection
scheme in which the offspring compete with the parents for population slots and
where, if N is the population size, the best N individuals from the
combined parent-offspring pool make up the next generation [Eshelman, 1991]. The
probability of crossover was 1.0 and the probability of mutation was set to
0.05. We initialized ![]() of the population with injected cases, the rest of
the population was generated randomly.
of the population with injected cases, the rest of
the population was generated randomly.
Figure 6 plots the number of problems attempted on the horizontal axis versus the generation that the best solution was found. It compares a randomly initialized GA with a CIGAR over ten runs with different random seeds.
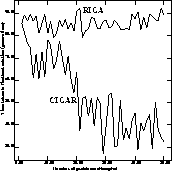
Figure: Number of problems attempted versus time taken to solve a problem
The figure shows that as the number of problems attempted increases the time taken to solve a problem decreases for CIGAR while the randomly initialized GA takes about the same time. After about half of the problems have been attempted there is a statistically significant decrease in the time taken to solve a problem.
We also compare the quality of solutions as the number of problems solved increases for the RIGA and CIGAR in Figure 7 over ten runs with different random seeds.
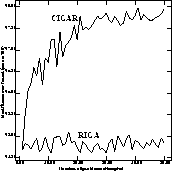
Figure: Number of problems attempted versus best fitness ever found
CIGAR improves its performance as it attempts more problems while the randomly initialized GA's performance stays about the same.