Indexing is a mechanism which allows rapid access to
some associated data. Thus, instead of having to search the space of all
possible appearances and explicitly reject invalid predictions through
verification, indexing inverts the process such that only the more
feasible predictions are considered. The idea here is to arrange the model
group appearances in an index space offline. During recognition, feasible
predictions can be found by indexing into this space. Indexing is of
fundamental importance for making AFoVs practical for ATR. We will perform
systematic study of indexing, addressing critical issues such as:
what information needs to be stored in the index table?
how should this information be generated?
how should the indices be computed and how stable will they be with
viewpoint changes?
what indexing mechanisms should be more appropriate?
We have
used hashing table in our past work. However, hashing is not efficient for
retrieving nearest neighbors since it does a range search. In this
project, we will consider a more efficient indexing scheme: k-d tree
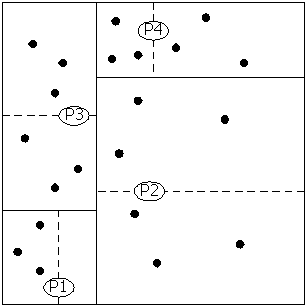
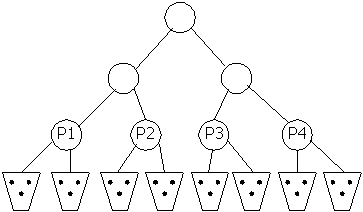
search. K-d tree (see Fig. 1) is a data structure which partitions
the space hierarchically using hyper-planes. The partitions are arranged
hierarchically to form a tree.
Figure 1. Two-dimensional k-d tree distributed over 4
processors