|
The recognition scheme
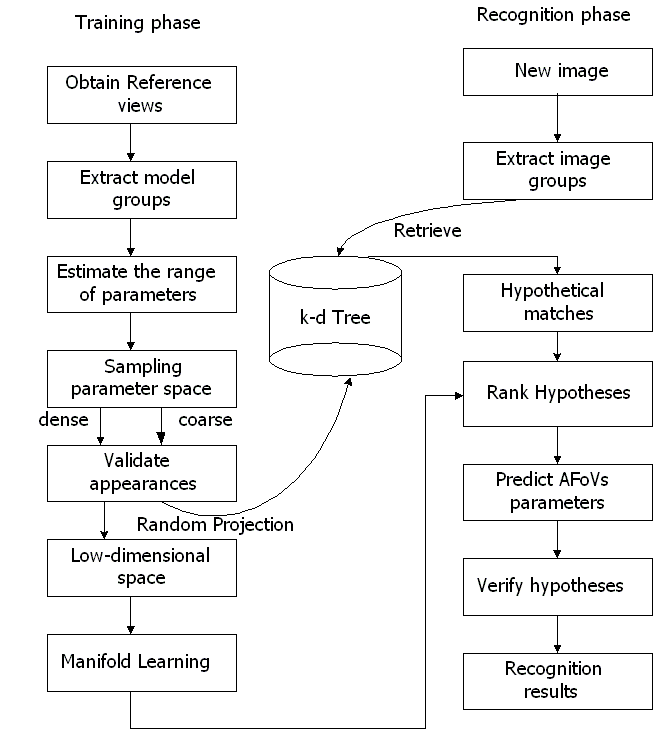
(shown in Fig.1) is based on two distinct stages. The first stage relies
on indexing. However, to keep space requirements low we index only a
sparse number of sampled views per model. To improve the quality of
hypotheses generated during recognition, we have replaced hashing, which
performs a range search, with a more powerful indexing scheme based on k-d
tree. In the second stage, we learn the manifold formed by a dense
number of sampled views per model using the EM algorithm. Learning takes
place in a "universal", lower-dimensional space computed through random
projection (RP). The only information that needs to be stored at this
stage is just a few parameters for each manifold. |